freistil News
The risk that unencrypted web communication creates for both website owners and individual website users can be significant. That’s why encrypting traffic via SSL (Secure Socket Layer) and TLS (Transport Layer Security) has become indispensable for both B2C and B2B websites. If you are transmitting sensitive private data over the internet, SSL is an important additional security layer.
But simply enabling SSL in a web server configuration file isn’t enough any more. Over time, the SSL/TLS protocol suite has become more complex and, unfortunately, a popular target. BEAST, Heartbleed, POODLE and now FREAK - these are only the better publicised exploits that threatened encrypted communication on the web over the recent years.
Additional to performance and availability, security is also a key factor that defines the quality of our Managed Hosting Platform. That’s why we’re putting significant effort into continuously optimising the setup of our dedicated SSL offloaders. These machines run at the edge of our infrastructure and take the compute load that decrypting traffic to and encrypting traffic from our customers’ websites creates off your Drupal and WordPress boxes.
The result of our efforts is that Qualys SSL Labs gives freistilbox an excellent A rating:
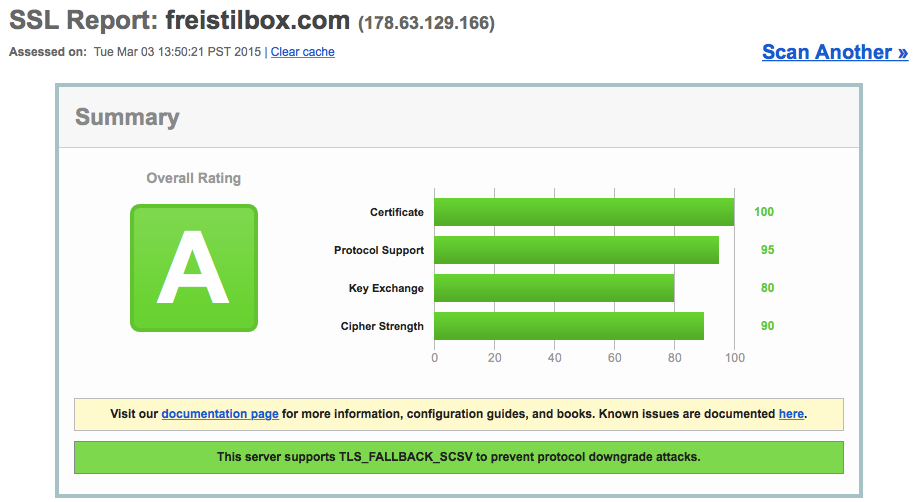
With the Qualys SSL Server Test, you can see for yourself how well other hosting providers secure their customers’ web traffic:
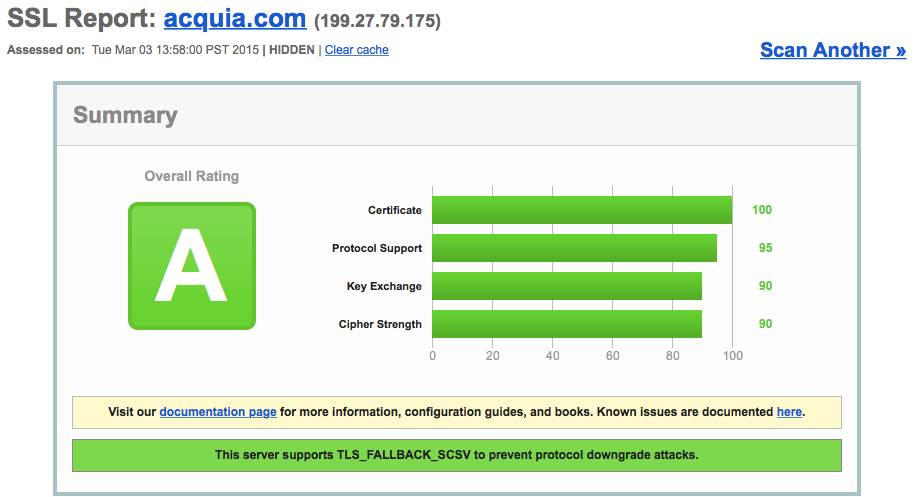
Acquia: The ELB engineers at Amazon obviously have done their homework.
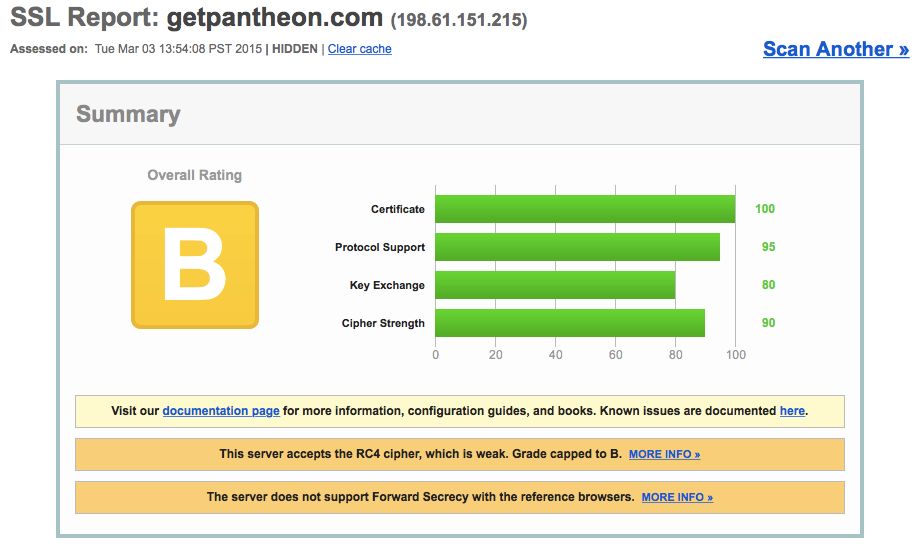
Pantheon: Solid but room for improvement

WPEngine: Very good with only a tiny flaw
Your customers trust that you take their security seriously, and losing this trust can break your business. That’s why running your Drupal and WordPress websites on our managed hosting platform is the right thing to do. Our engineering team has only one goal: to let you work efficiently and — just as important — sleep peacefully.
Jochen Lillich
04 Mar 2015
In the past, trouble with asset file permissions caused us a lot of support requests. The emphasis here lies on “in the past” because we’ve finally sorted that issue out once and for all.We’ve simplified the file permissions on the shared storage system so that all asset files have a single owner regardless of how they’ve been created, be it by the web application itself or by a developer logging in via SSH. This change finally puts an end to file access problems and, we hope, makes asset file maintenance much less annoying.If you have any questions about this change, we’d love to hear from you in the comments!
Jochen Lillich
02 Mar 2015
Every freistilbox customer gets their own dual-node Varnish cluster, so we have a lot of experience in tuning the cache configuration for Drupal or WordPress websites. I’ve distilled some of our most important best practice tips into a talk called “Getting the most out of Varnish”.
Here’s a recording from DrupalCamp Galway in November 2014:
And here are my slides:
If you have any questions about Varnish tuning, just leave me a comment!
Jochen Lillich
23 Jan 2015
“What happens in Barcelona will definitely not stay in Barcelona.” That’s one way to describe how we felt when, at the end of our company retreat, we looked back on the past week. This was the first time we did “freistil Days” and it had significant impact on how we work as a team.
Getting the band together
Working as a virtual team certainly has a lot of advantages but there are obvious limitations to social interaction when it’s done over digital connections. We felt that we could learn to know each other better meeting in the real world. After reading how other distributed companies like Buffer, Automattic and Zapier found regular team retreats a great boost to coherence and trust within their teams, we decided to try it out ourselves. So we started preparing our very own “freistil Days” and finally boarded our flights on 6 October 2014.
In order to get a bit more Vitamin D, we had chosen sunny Spain as our first destination. Via airbnb, we booked an apartment in El Poblenou, a coastal suburb of Barcelona. The apartment turned out as nicely decorated as it was pictured on the website and offered everything we needed. After arriving, we first went out for groceries and then started preparing our week by moving the TV set to the dining table and connecting it to an Apple TV. Being able to share a big screen proved ideal for group coding and presentations.
Our standard schedule for each day looked like this:
- 08:00 Breakfast
- 09:00 Presentation
- 10:00 Workshop
- 13:00 Lunch
- 14:00 Freestyle
- 16:00 Workshop
- 18:00 Freestyle
- 19:00 Dinner
- 20:00 Freestyle
We’re freistil IT, so “freestyle” had to be built into the schedule. We wanted to make sure we had enough time to take care of daily business and do spontaneous things, with the group or alone. That’s why we put in multiple “freestyle slots” during each day. Additionally, we reserved a day and a half for excursions throughout the city.
Show and tell
The presentation slots in the morning were meant as an opportunity for each team member to talk to a friendly audience. We mainly used these slots to present our personal V2MOM’s. And it turned out that learning more about each coworker’s Vision, Values, Methods, Obstacles and success Metrics gave us a much better understanding of each person’s position within the company.
In another presentation slot, I went into the details of how my responsibilities are changing with my steady shift from the technology side to the entrepreneurial side of the business.
Team learning
The most important part of our retreat was the workshops. From a long list of topic suggestions, we had picked two related ones: Sharing Chef best practices, and integrating serf into our infrastructure.
Chef is our most important IT tool, it controls every one of the about 400 servers we operate. This makes improving our infrastructure coding skills an obvious goal. We started with discussing the Chef cookbook development workflow and dove into the different cookbook testing tools. As we progressed, we were getting more and more excited to use our new learnings in practice.
So when we found that the existing serf cookbooks didn’t quite meet our newly formed quality standards, we decided to create one ourselves. In order to keep things simple, we started by building basic functionality and adding tests afterwards. Then we got more ambitious and, in true TDD spirit, wrote tests first. The result was a cookbook that will serve us as a reference in terms of code clarity and test coverage.
But I’d paint an incomplete picture if I only mentioned our technological advances. During our work, we had more than one heated discussion. This got us to realise that we tend to hold back much more when we’re talking via webcam, which might in some cases become a breeding ground for dissatisfaction. One of our core values at freistil IT is transparency, so we agreed to be open with each other and not to hold back when ever there is something bothering us.
Business as usual
Although the freistil Days were completely different a setting to our normal work days, we were not living in a bubble. Daily business had to be done, a big part of which is dealing with support requests. In planning our schedule, we had thought that the freestyle slots would be sufficient to take care of the most important stuff. But to pit work duty against spare time isn’t a good idea and turned out to always be a bit of a struggle.
Then there’s also the unexpected stuff. A few days into our company retreat, resolving a severe system outage cost us almost a whole day. And the next morning, another incident made it necessary for us to change our plans again.
All work and no play?
We had reserved ample time to get away from the screen and out of the apartment. A more frequent destination turned out to be the small Italian restaurant down the road that served really great pizza. The Rambla de Poblenou, a restaurant mile, provided us with a huge choice of alternative places to eat. I also found a Starbucks at a nearby shopping mall where I spent some time reading.
Barcelona is known for its architecture, so doing a little sightseeing was a must. Among other things, we took a walk through the Park de la Cuitadella, watched happy people carry their newly released iPhone 6 out of the Apple Store, and had some tasty organic burgers at Kiosko. On the way, we enjoyed the city’s impressive architecture, old and new.
More often than not, we finished our day by going to the beach. To be honest, walking barefoot in the sand while the folks back home were turning on the heating caused me an awkward mix of giddyness and guilt.
What we learned
The most important lesson from our first freistil Days was that meeting in person regularly is important. Spending time with one another allows for different behaviours and dynamics than chatting in a text or video window. We found that it actually didn’t matter as much on which project we worked as that we did it at a shared place. It’s about the journey, not the destination.
Our progress as a team came at the expense of our customers as we didn’t spend as much time as usual for responding quickly and elaborately to support requests. Next time, we’ll schedule dedicated time slots for ongoing business in order to avoid dissatisfaction, both on our and our customers’ side. We’ll also make a point of informing customers in advance that we’re going to work under exceptional circumstances for a while.
Here is some feedback from our retrospective:
- “Even more important than our achievements is what happened between us.”
- “We need to inform and prepare our customers before we leave for the retreat.”
- “Next time, let’s use our Twitter account to share updates.”
- “Having a clear schedule and goals was helpful.”
- “A week of team experience is much more effective than single-day events like a BBQ.”
- “It’s been an intensive week, both in terms of productivity and emotions.”
Finally, some practical tips:
- Chose an apartment with a kitchen over a hotel. Preparing meals is teamwork, too!
- Bring a 3G hotspot and buy a local SIM card with a data plan so you can share mobile connectivity.
- Pack an Apple TV or a Chromecast so you can use the big screen TV in the apartment for presentations and group coding.
- Don’t overschedule. Leave enough flex time for group dynamics to develop.
Our first freistil Days had significant impact on how we function as a team. While we’re very happy about all the advantages we gain from working as a remote team, being able to actually compare how working as a co-located team is different helps us avoid the downsides of the virtual office. That’s why we’re going to make regular freistil Days part of our company culture. From now on, we’ll gather every five months at a different place. I’m already looking forward to March!
Does your company do retreats, too? What’s your experience? What is your most important recommendation? Leave your tips and questions in the comments!
Jochen Lillich
13 Jan 2015
Long before the actual vote took place on September 16 2014, The Scottish Independece Referendum drew a lot of attention in all over Europe. So, when Paul Linney from madewithcustard got in touch with us a few weeks before the event, we were thrilled about the opportunity to host scotlandreferendum.info. Together with web agency Post Creative, Paul was in the process of building the website for the City of Edinburgh and scouting for a WordPress hosting solution that would be able to sustain stable operation even during the visitor peaks expected for voting night.
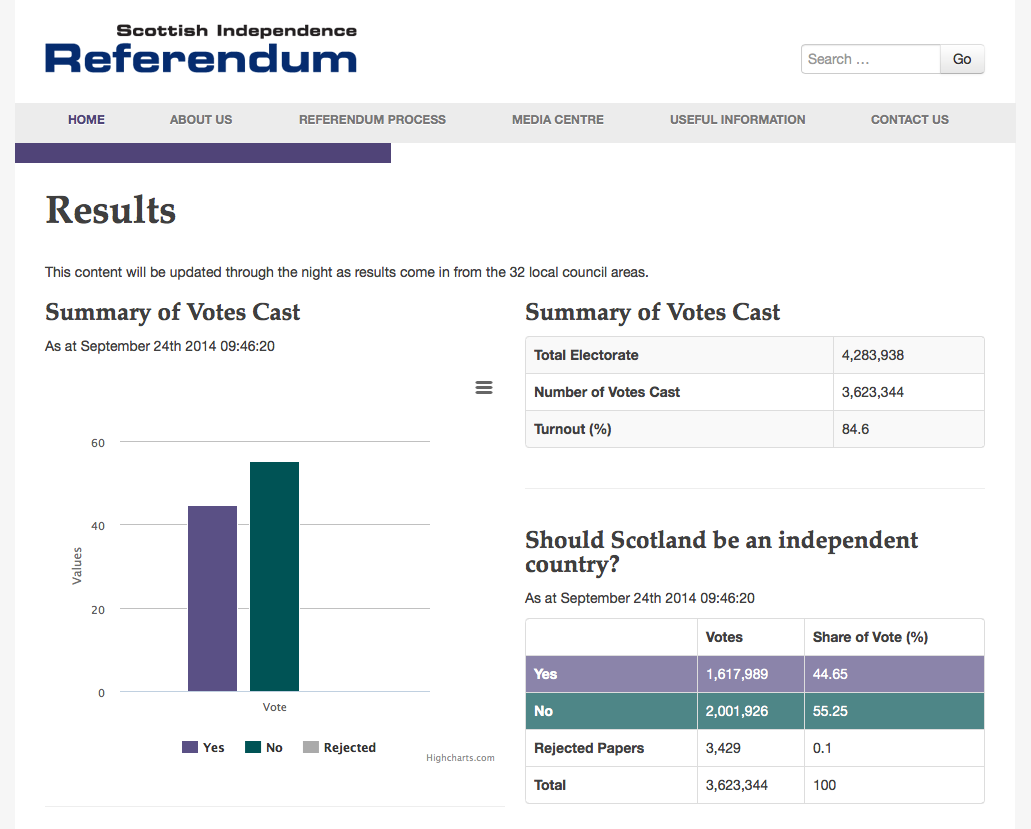
To prove the reliability of our platform, we did a performance test on a freistilbox cluster set up with two freistilbox M. Paul was surprised to find much better test results on freistilbox than what he had seen on similar setups with other well-known hosting providers. The freistilbox cluster delivered a peak performance of 1337 requests per second with 0.11% timeouts.
Before we go into how freistilbox handled the traffic on voting day, a question: How can it deliver this kind of performance? One aspect is that we run our hosting platform on bare-metal infrastructure. Using dedicated hardware gives us full control over its resources. In comparison, public cloud infrastructure is designed as a black box for its users who can’t prevent “noisy neighbours” from eating up CPU capacity, disk I/O performance or network bandwidth. Another important aspect is network latency. Sometimes, website performance suffers simply because cloud machines are talking to each other over long network distances. For freistilbox, all important communication happens within a dedicated data center rack. In our experience, this setup is perfect for fast and reliable content delivery.
When referendum day came, our ops team started monitoring the site’s performance more closely. We were prepared to add additional boxes as soon as demand would require it. When the vote counting results started to come in after 10pm, visitor numbers climbed significantly, as expected. freistilbox handled all traffic peaks gracefully and we didn’t have to intervene at any time.
While the Referendum’s results surely were disappointing for many Scots, our customers were delighted by how freistilbox had performed. Shortly after the event, we got the following email from Post Creative’s Nova Stevenson:
“I’ve been really impressed with the speed of the Scottish Referendum website on your platform so I’ll be coming back to you to discuss moving our sites over to you in the next few weeks.”
We can’t be happier about this outcome. freistilbox proved once again to be a world-class hosting platform for Drupal and WordPress. This is our vision and every day (and on many nights, too), we put in all the necessary work to make it reality.
Jochen Lillich
07 Jan 2015
On October 14th, the so-called POODLE vulnerability in SSLv3 was published. We remediated this security issue by disabling SSLv3 throughout the freistilbox infrastructure.
To further reduce risks, we’re deprecating SSL certificates using the SHA1 signature algorithm. After thorough review, we have concluded that this change should not affect the majority of freistilbox customers. As you can see on the Digicert Compatibility Chart, all recent web browsers already support the newer SHA256 standard.
If you’d like to check if the SSL certificate for your website still uses the weaker SHA1 algorithm, we recommend using the Qualys SSL server test. The test result should look similar to this:
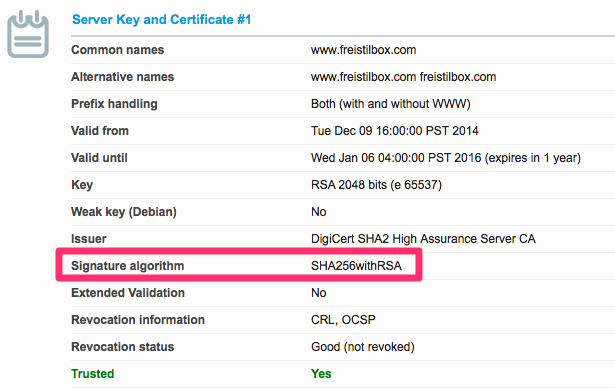
If your certificate still uses SHA1, simply send us a support request and we’ll take care of getting it reissued for you.
Thank you for your trust and continued business,
—your freistilbox Team
Jochen Lillich
19 Dec 2014
Last month, Netways held their annual Open Source Monitoring Conference. System engineers from Germany and abroad came to Nuremberg to learn more about tools that help us better understand our IT infrastructure.
Netways was gracious enough to invite me as a speaker and the video of my talk just became available. I gave an introduction into Sensu, a great monitoring framework that we started to use when Nagios could not handle our steadily growing number of checks any more.
I had a lot of fun at OSMC. Netways not only did a good job in selecting interesting talks by competent speakers but also went to great lenghts with the catering during the day and an awesome conference dinner. For me, OSDC and OSMC also are welcome opportunities to meet former colleagues again, and OSMC 2014 didn’t disappoint in this regard either.
Next year, OSMC will have its 10th anniversary and I’m looking forward to both the conference and the party!
Jochen Lillich
18 Dec 2014
The end of the year is approaching quickly and as always, we’re going to take it as an opportunity to recharge our batteries. This means that from 24 December 2014 to 4 January 2015 , we’ll provide emergency support only.
Of course, should incidents occur that impact the operation of your production websites, our 24/7 on-call will take care of them.
If you need some last-minute engineering support for anything else (launching the new reindeerrental.com, adding SSH access for additional elfs etc.), we recommend you send us your wishes as early as possible! Like Santa, we’ll handle each of your requests to our best ability, but we’ll close our workshop on Christmas Eve. (We’ll be back in far less than a year, though.)
From the whole freistil IT team, thank you for an awesome 2014, have a happy Christmas and a great start into the new year!
Jochen Lillich
08 Dec 2014