freistil News
You may be wondering why we don’t have an “Enterprise” column in our pricing table. It looks like everyone has such an offer, after all.
The reason is: With freistilbox, we decided to not make Enterprise-grade hosting the highest(-paid) tier of our product. Instead, we’ve built the whole platform with Enterprise quality, from the smallest configuration upwards.
With other vendors, you get much less powerful Drupal and WordPress hosting if you choose one of their lower tiers:
- no distributed hosting architecture where every service runs on its own redundant and diligently configured server infrastructure,
- no SSL offloading,
- no storage network with multiple file copies,
- no SSD-based database clusters,
- etc. etc.
In other words, you don’t get much more than a managed VPS. If your website needs real performance and availability, your only option is their offering with that impressive “Enterprise” label (and price tag).
With freistilbox, things are different — and simpler! The only decision you have to make is what capacity you’d like to start with. It doesn’t matter if you choose a single freistilbox S or a 4xM power cluster; you’ll always get the full benefits of our hosting platform. Regardless of its size, every customer setup is based on the same high performance hosting architecture with SSL offloading, load balancing, redundancy and bare-metal performance.
freistilbox is Enterprise hosting from the start.
Jochen Lillich
04 Dec 2014
Working as a remote team has many advantages and we’re very happy to have the freedom and flexibility it gives us. We can not deny, though, that it has a significant downside: our personalities and therefore our interactions have a lot more aspects than we can ever convey sitting in front of a webcam. You can’t really learn to know a person fully without experiencing how they think and act in different situations.
That’s why we decided to have regular events where the whole team comes together at a common location for a few days. During these events — we’ve named them “freistil Days” — we share an apartment, we eat, talk, work and play together. The idea of a company meetup is not new and we’ve looked at how other distributed companies like Automattic, Buffer, Sqwiggle and Zapier have done theirs.
And finally, freistil Days are about to happen for the first time: On Monday, we’ll fly to Barcelona where Markus, Philipp and I are going to enjoy working as a co-located team for 8 days. If you’re interested in what’s happening there, be sure to follow our Twitter account!
Jochen Lillich
03 Oct 2014
freistilbox is a fully managed hosting platform. That means that we do everything that’s necessary to run a reliable hosting service.
Last week, a new software security threat with a catching name raised its ugly head: Shellshock is a security flaw in the widely used command-line shell “bash”. This security flaw can be exploited to issue an arbitrary command to a server to be executed. Troy Hunt has the technical details.
After this security weakness became widely known on Wednesday and security fixes were made available soon after, we immediately tested and installed them. Since then, we got two follow-up bash updates with additional fixes that we rolled out in the same swift fashion.
If you prefer to sleep peacefully, knowing that we take care of hosting security, why don’t you check out all the other advantages of freistilbox?
Jochen Lillich
29 Sep 2014
August has been a bit more quiet due to vacations. Unfortunately, my own vacations came in the way of finishing and publishing my sum-up for July. That’s why I’ll compare our numbers for August to those I published in my sum-up for June.
In August, our DevOps support took center stage. We spent a significant amount of time working with customers on launching new websites and optimising existing ones. Performance tuning is one of the main concerns here. freistilbox certainly offers everything a high-traffic website needs to master traffic peaks without hiccups. Achieving reliable performance, though, requires optimising the web application so it can fully take advantage of our hosting platform. That’s where our engineering support shines with deep expertise in Drupal and WordPress tuning. We collaborate with our customers via phone, email or web chat as soon as any question or issue arises until it is solved.
freistilbox
We’re continuously expanding our infrastructure. Over the recent weeks, the number of websites we run on freistilbox increased by 22% to 394. With the number of websites, our web traffic also made a jump of 24% to 15.09 TB. Although a growing infrastructure means more points of failure, our monthly uptime stayed at an excellent value of 99.87% (+0.01%).
Help Center
As I’ve mentioned above, delivering DevOps support is taking up a growing portion of our time. The August numbers for support requests reflects that. That month, we received 29% more tickets (193) than in June. Nonetheless, we’ve kept our ticket backlog at 39 because we were able to resolve 161 tickets, a whopping 50% improvement!

Unfortunately, our average reaction time went up significantly by 144%. As the chart shows, we slightly improved in the area of quick responses but much higher percentage of customers had to wait for more than a business day, compared to June. We’ll investigate if that’s due to the nature of the actual support requests or if we need to tweak our Help Center processes. Since satisfaction feedback remained at a perfect 100% “good”, we’re confident that we’re still doing a great job.
Operations
With more websites a growth in IT infrastructure is to be expected, and the number of servers our ops team has to maintain actually increased by 24%. 373 hosts means that our server:sysadmin ratio is 187:1.
The number of metrics we collect even grew by 26%. We’re now collecting 124,642 metrics every 10s. In order to achieve the necessary I/O performance, we built a new metrics storage on SSD drives.
Causing us a bit of concern is the fact that the amount of on-call alerts went up by 20% in August (1378 alerts total). So it’s exactly at the right time that PagerDuty published “ Let’s talk about Alert Fatigue”. We’ll especially have to dig deeper on the aspect “Cut alerts that aren’t actionable & adjust thresholds”. Another important improvement will be eliminating alerts that only get triggered as a consequence of previous alerts (for example, identical shared storage space warnings from all the boxes of a freistilbox cluster).
Community events
While our web hosting platform only runs PHP-based applications, we use Ruby for a lot of internal applications and tools. That’s why Markus spent the first August weekend attending eurucamp at the Hasso Plattner Institute in Potsdam. It was amazing to see the inspiration he brought back. This can only be good for our latest Ruby-based project, the freistilbox Hosting API. We’ll let you know more on this important undertaking later. So stay tuned!
Jochen Lillich
16 Sep 2014
On Sunday, 2014-08-03, freistilbox operation was severely disrupted due to a power failure at a datacenter.
We apologise for this outage. We take reliability seriously and an interruption of this magnitude as well as the impact it causes to our customers is unacceptable.
What happened
On Sunday, 2014-08-03, at 12:34 UTC, our on-call engineer was alerted by the monitoring system that a number of servers suddently went offline, and the list was quite long. This indicated a network outage, and we posted a short notice to our status page. We then immediately contacted datacenter support. While we didn’t get a direct answer first, the datacenter posted a first public status update at 12:54, explaining that server room RZ19 suffered an outage.
Since one of our server racks is located in this server room, the impact of this outage was severe. The affected rack hosts all kinds of servers including database and file storage nodes. Without these services, even application servers outside of RZ19 weren’t able to deliver content any more.
Since we run the nodes of our database clusters in different server rooms, we executed a failover procedure to the standby nodes of the affected databases. This restored operation for a part of our hosting infrastructure.
At about 13:00, our servers started to come back online. When we checked their uptime, we realised that they must have just had started up, so we suspected a power outage. This was confirmed when the datacenter announced that RZ19 had suffered a “brownout” that caused its servers to reboot. Later, the ISP added that a whole datacenter location suffered a power outage. The UPS systems of all server rooms had been able to compensate until the power generators had started up – with the exception of RZ19.
At about 14:00, most of our servers were running smoothly again. A few of our database servers had suffered data corruption and since we had already switched to their standby nodes, we decided to repair them later. At that time, it was more urgent to replace application boxes that still had not come back. Some of our customers choose to run single-node freistilbox clusters and the websites running on these boxes were still down. We launched new boxes on servers with spare capacity and at about 15:00, our infrastructure was fully functional again.
What we’re doing about it
Since we don’t run our own datacenters, we depend on our hosting partners when it comes to hardware infrastructure (servers, network, power, cooling etc.). We can’t prevent power outages, only trust that our infrastructure providers take all the necessary measures to prevent them.
What we can do ourselves is build our hosting architecture as resilient as possible in order to minimise the impact of a power outage. We have already built in a lot of redundancy into freistilbox. This enabled us, for example, to quickly switch to non-affected database servers as we did at the beginning of this incident. We have identified a few points, though, where an outage can cause bigger parts of our infrastructure to fail.
The most critical one of these points is our current storage technology. While it comes with data replication features (of which we make use, of course), it is hard to distribute data over server rooms or even distant datacenters without running into network latency issues. That’s why we’re currently testing alternative solutions that don’t have this weakness. As a beta test, we’re already running our own company freistilbox cluster (the one that’s hosting this website) on one of these alternatives. This means we’ll be able to further improve our storage resiliency very soon.
Another point is the private cloud infrastructure on which we run the application boxes of our customers’ freistilbox clusters. By adding more system automation, we’re going to minimise the time it takes us to spin up replacement boxes when that becomes necessary, for example and especially during an outage.
Again, we sincerely apologise to all our customers affected by this outage and thank them for their continued trust.
Jochen Lillich
13 Aug 2014
In terms of Drupal events, there is no summer break; the best example being the DrupalCamping going on in Wolfsburg at the moment. I’m so sad that my schedule doesn’t allow me be there and camp with my German Drupal friends!
Fortunately, I get to attend DrupalCamp North East in Sunderland next weekend. I’m very much looking forward to fly over to the UK again for the third time this year because I enjoy the Drupal community there as much as the ones in Germany and Ireland.
Since community is one of our core values at freistil IT, we try to participate at these events as actively as possible. I’m proud to announce that my session proposal about “ DevOps with Drupal” has been accepted and I’ll do my very best to explain how embedding development in operations and vice versa can improve working with Drupal in a great way.
If you’re also going to be at DrupalCamp NE next weekend, give me a shout via Twitter! I’ll happily arrange sharing a few drinks and great news about our new Partner Programme!
Jochen Lillich
21 Jul 2014
Philipp started in May as the first employee of freistil IT Ltd. He is a long-time system administrator with a lot of experience in operating web-scale infrastructure.
Since May, Philipp has been going through Operations Bootcamp, a training series where new sysadmins learn everything they need about our tools, processes and especially all the software we run on our servers. He also started taking care of day-to-day tasks like support requests or the replacement of old infrastructure.
Here’s what Philipp makes of his first weeks at freistil IT:
Life before freistil IT
“My job before freistil was nine years of corporate work that I don’t want to have missed, but I’m really happy that it’s over now. I’ve learned a lot in different teams and environments over the time, and I had the chance to learn from some of the best developers and IT system cracks I’ve met so far. But being a small wheel in a large machine can be very frustrating, and from some point on, there’s only little chance to level up.”
What made freistil IT stand out?
“Let’s say “nine years are enough”! :) I felt the need for something new, and it should be something smaller, more flexible, and should not have anything to do with operating JBoss application servers. ;) Being given the opportunity to work remotely is a completely new experience to me. I wanted to try this way of working and the job offer from freistil was the only one I got featuring this. And last but not least, I knew Jochen before, so I knew the start would be a bit easier than in a completely new working environment.”
What are your first impressions of the team and culture?
“The team (and here, I refer more to Jochen and Markus than to myself) is highly skilled and quite enthusiastic. My learning curve is not a curve at all, it’s more like a vertical line, which can be strenuous sometimes, but at the end of the day is exactly what I was looking for. The culture is new, fresh, and free. Fantastic when you’re coming from a musty corporate environment.”
What do want to achieve with the operations team?
“Keep it up and running, but also pull it to the latest trends and never let the needs of our customers out of sight. And I’m looking forward to get more involved in the Open Source community, which is much easier here at freistil IT, I think.”
Thanks, Philipp! We’re happy to have you on our team and are looking forward to a great time!
Jochen Lillich
18 Jul 2014
If you’re familiar with my monthly retrospectives, you know they come with a lot of numbers. Let’s start with these: 7:1 ! That’s what proper teamwork looks like, folks!
At freistil IT, we enjoy our effective collaboration, too. While Philipp is still going through Operations Bootcamp (for an IT infrastructure like ours, there’s a lot of ground to cover), he’s also started to assist in production changes. We’ll soon post a blog entry with his first impressions of our small business. Markus decided to examine the life of a digital nomad for a few weeks: He’s traveling around Germany with his family in a camping van and takes care of our servers and your support requests via mobile broadband and local WiFi hotspots. And I’m enjoying a magnificent Irish summer at home, trying not to get a sunburn!
freistilbox
In June, more than 40 new websites launched on our hosting platform, increasing the total by 15% to 324. With the number of websites, our total traffic also grew: We delivered 12.15 terabytes of content in June, 3.7% more than in the month before.
Another number makes us very happy, too: We managed to keep the overall availability at an excellent level of 99,97% (99.98% in May).
Help Center
While the number of engineering support requests was exactly the same as in May (150), our resolution rate somehow was 15% lower with 107 tickets compared to 126 in May. We’ll need to have a look at possible causes.
On the other hand, we’ve improved our average reaction time by whopping 35%, from 9.7 hours down to only 6.3h. The reaction time breakdown below shows that we were able to cut the number of customers that had to wait more than 24 hours for a first reply by almost 60%!
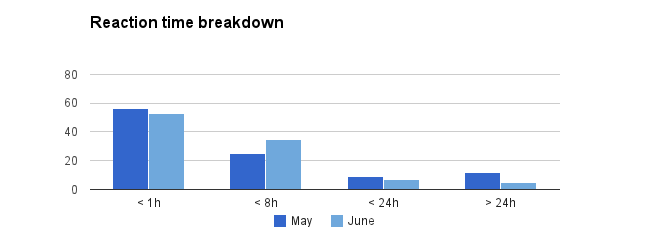
We’re also proud that we’ve kept a perfect score of 100% positive customer feedback. Judging from comments like “Very friendly and helpful. My request has been solved very quickly. Thanks for that.”, we’re doing a good job.
Operations
With the continuing success of freistilbox, our infrastructure grew by 6% to 300 servers. Our metrics monitoring even increased by 9% to 98,951 metric points that we collect every 10 seconds.
That at the same time the number of on-call alerts went down by 13% isn’t something we’ll complain about. ;-)
Community events
June was a bit less conference-heavy and while I manned the stations, the new ops team went on tour:
-
Markus attended WordCamp Hamburg and gave a talk about automated WordPress development setups. When he sat down with our friends from Palasthotel to demonstrate our communication tools, it turned into an impromtu BoF on remote working!
-
Just a few days later, both Philipp and Markus went to the Netherlands and brought back at lot of inspiration from DevOps Days Amsterdam.
{kind=link}
This month, I’m looking forward to flying to England again for DrupalCamp North East. If you’re going to be there, shoot me an email and let’s have drinks together!
I’m also proud that I’ve been selected to present among the high-calibre speakers at the Open Source Monitoring Conference in November.
Usually, the coming months will be a bit more quiet because many of our customers take their vacation time (there it is again, that word…). Since our internal backlogs are looong, there won’t be any boredom, though. And of course, we’ll always be there if you need us!
Jochen Lillich
10 Jul 2014