freistil News
In Drupal 7, database logging via the “dblog” module is enabled by default. On high-traffic websites, this can become a problem. When Drupal generates lots of log entries, they can cause significant write load on the database and fill it up quickly. We’ve seen many database backups take longer than an hour because the “watchdog” table was multiple Gigabytes big, and more than one website database bog down under log write load.
The best solution is of course to to fix all PHP notices and warnings to reduce logging overhead. But you’ll still want to have a way of preserving important events in order to analyse them if the need arises. With the “syslog” module, there’s a better alternative to “dblog” and we’ve recently added syslog support to freistilbox. All log entries will simply be written to a log file in your website’s “logs” directory.
If you use our pre-built configuration snippets (and you should), all you need to do is to enable the “syslog” module. Our configuration snippet already comes with all the right module settings. And don’t forget to disable the “dblog” module!
Jochen Lillich
23 Jun 2015
A few days ago, a new SSL vulnerability called “Logjam” was published. The attack exploits weak “Diffie-Hellman” (DH) parameters in incorrectly configured SSL/TLS servers.
We decrypt incoming SSL traffic right on our Edge Routers in order to enable content caching for both plain-text and encrypted web requests. Since we follow best practices, we don’t use any of the vulnerable cryptography. No changes in our Edge Routers were necessary to mitigate LogJam.
In order to deliver the best SSL processing performance possible, our Edge Routers prefer key exchanges based on “Elliptic Curve” cryptography, thus avoiding problems with DH altogether.
We are proud that the SSL configuration of our Edge Routers is rated “A+” by SSL Labs, and happy to give you peace of mind about the security of your website traffic.
Jochen Lillich
28 May 2015
Bring together Drupal developers, themers, end users and those interested in learning more about Drupal — that’s the mission of the Drupal Open Days, the biggest DrupalCamp in Ireland. It’s happening again, and we’d like you to be there, too!
On May 22 and 23, we’ll have two days of talks, sessions and collaborative discussions about Drupal. Like last year, the main event will be at the Guinness Enterprise Centre and we’ve reserved space at nearby pubs to continue our conversations in the evenings after the sessions.
The Open Days team is doing amazing work behind the scenes preparing everything. Please help us spread the word so that lots of people interested in Drupal will make this event a great success!
We’ve gathered a bunch of brilliant speakers, first of all Emma Jane Westby with “Managing Projects the Drupal Way”. Peter Sherrard, FAI Communications Director, and Daniel Walsh will present “The Football Association of Ireland’s Drupal & UEFA API Experience”. It’ll be two days packed with information about how to use Drupal successfully!
As a company based in Ireland and, more importantly, a part of the Irish Drupal community, freistil IT is happy to support Drupal Open Days as a Gold Sponsor. I’ll be around on both days (and nights), so don’t hesitate to chat me up if you’re interested in having your Drupal website(s) run by experts.
It’s important that we demonstrate that Drupal has critical mass in Ireland. So again, please tell your friends, colleagues and customers to join you at Drupal Open Days.
Sign up now and be a part of the greatest Drupal meetup in Ireland!
Jochen Lillich
06 May 2015
Our current hosting product freistilbox is highly scalable, and compared to other enterprise hosting platforms, its pricing is unrivaled. But more often than not, customers tell us that not everyone actually needs a full Drupal or WordPress cluster which can scale to hundreds of websites. That’s why, after five years, we decided to launch freistilbox Solo, our new plan for web developers who need powerful managed hosting for a single website.
Today, we’re going to tell you the details of what we’re up to.
Developer experience
freistilbox Solo is designed from the ground up to support and enhance the workflow of Drupal and WordPress shops.
Development speed is one of the most important aspects in web projects, so it’s vital that your hosting platform offers an efficient way to deploy changes. That’s why freistilbox Solo will use the same instant deployment approach as its bigger sibling: the moment you push a change to your Git repository, it’ll be published on freistilbox Solo.
In order to support the usual development phases of development, staging and production, each freistilbox Solo account comes with three separate website instances. You can base all three on the same Git repository because our deployment process will automatically enable the correct configuration for each staging environment.
Alternatively, you can assign a specific branch of your application repository to each instance. For example, you could simultaneously work on and deploy from a “development”, “testing” and “production” (aka “master”) branch.
Visitor experience
All your website visitors, human beings and search engines alike, put a high value on performance. Being able to generate and deliver content quickly has a direct impact on both your sales and search engine rankings.
We will offer freistilbox Solo in three tiers that differ in capacity:
- freistilbox Solo S with 8 Processing Units and 10 GB of storage space,
- freistilbox Solo M with 12 Processing Units and 20 GB, and
- freistilbox Solo L with 16 Processing Units and 40 GB.
In case you’re not familiar with the term “Processing Units”, that is our metric for how many concurrent Drupal or WordPress requests freistilbox can handle, so another fitting term would be “application workers”.
In freistilbox Solo, we use the same technology that serves our current freistilbox customers, only on less complex IT infrastructure. This includes a high-performance LAMP stack plus
- Memcache for maximum application performance,
- Varnish for delivering static content at 300 requests per second,
- an SSL terminator that enables caching of encrypted web sessions, and
- Apache Solr for high-speed content search.
As with freistilbox Enterprise, all these system components are optimised for running Drupal and WordPress. And since they connect without any network latency, freistilbox Solo will deliver your website content with amazing speed.
Service experience
While freistilbox Solo does not require the same infrastructure complexity as freistilbox Enterprise does, there is still a lot to do in order to let our customers work efficiently and sleep peacefully. freistilbox Solo is fully managed and our operations team will take care of all the work required to run your websites at full performance. For example, we’ll make sure that the hosting software is updated regularly, that your data is backed up and that performance bottlenecks get eliminated. If there’s some new technology that can benefit our customers significantly, we’ll try and integrate it into our hosting platform. And if (well, rather “when”…) something breaks, our ops team will get on it immediately, day or night.
We are convinced that web projects are the most successful when developers and operations folks work towards the same goal. That’s why freistilbox Solo customers will enjoy the same competent technical support as our freistilbox Enterprise customers. We won’t leave you alone when you need help running your website.
Countdown!
We’re a bit behind schedule but the launch of freistilbox Solo is getting nearer and we’re already very excited! Soon, we’ll reveal the pricing and the exact date when we’re going to make freistilbox Solo available.
We hope to see your website fly freistilbox Solo soon!
Jochen Lillich
04 May 2015
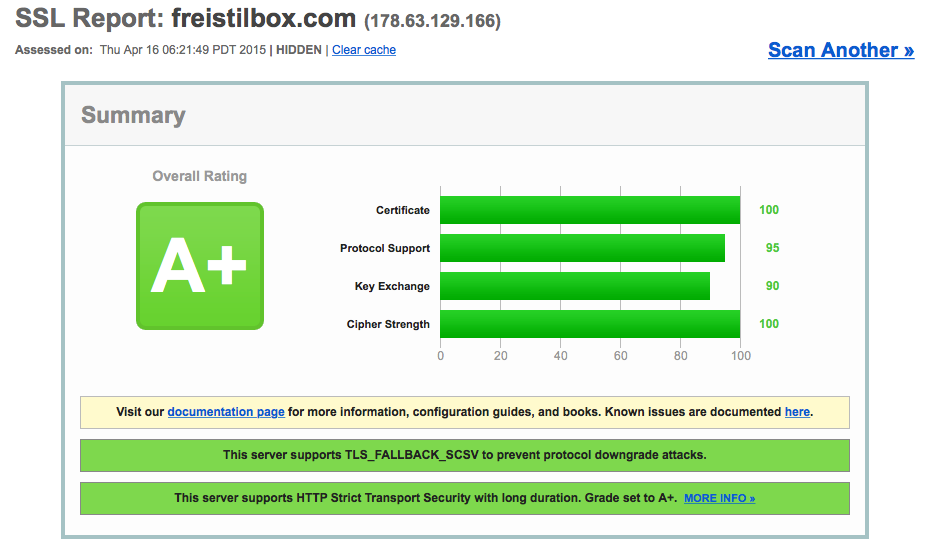
When we announced the Qualys SSL Labs A rating we got for the encryption quality of our Edge Routers in March, we knew that there still was room to improve. Our ops team kept tweaking the SSL configuration and we’re proud to present the result:
SSL Labs now rates our SSL security with A+!
Jochen Lillich
17 Apr 2015
TL;DR: This change affects the naming of your staging instance configuration files on freistilbox.
Staging has been built into freistilbox from the start. Being able to test changes on a staging instance before launching them in production has been an important feature for the majority of our customers, Drupal agencies and WordPress shops alike.
freistilbox makes it convenient to manage separate configuration files for staging environments within the same Git repository. In order for this to work, staging instances need to have a unique name that differentiates them from the “production” instance. So far, we’ve allowed our customers to choose this name freely. There’s “stage” and “staging”, “test” and “testing”, and one customer uses “stfu_stoopid_client” for reasons we don’t know.
A few weeks ago, we were shocked to learn that by giving our customers this freedom, we’re actually causing them what psychologist Barry Schwartz calls “The Paradox of Choice”. In Schwartz’s estimation, choice has made us not freer but more paralysed, not happier but more dissatisfied. Here’s his TED talk on this topic:
It became clear to us quickly that we can’t be a part of this. We’re here to take stress off our hosting customers, not to cause them additional pressure. That’s why we decided to stop forcing you to choose a stage name again and again.
In order to implement this change, we first had to endure the analysis paralysis mentioned in Schwartz’s research ourselves: what name should we choose? Doing a quick statistical analysis to find the most frequently used name in existing freistilbox websites was an obvious option. Instead, we decided to do a multi-week study of how our customers integrate the freistilbox staging process into their daily workflows, and the result will surprise you.
After sifting through a heap of conversation transcripts during a few late-night on-call shifts, we found that the most common conversation among website developers during user acceptance testing went like this:
“Did you make the change we’ve discussed yesterday?”
“Yup, I did.”
“And does it work?”
“Well, yeah, it’s working in theory.”
With these results, defining the new mandatory stage instance name became easy and we’ve already renamed all existing staging instances to “theory”.
Jochen Lillich
01 Apr 2015
Looking at its pricing, it’s not obvious that freistilbox is an enterprise-class hosting platform; it’s no secret that we’ve made running Drupal and WordPress websites on a multi-server infrastructure affordable. Our customers, web agencies and development shops, are amazed how quickly they reach ROI.
Many of them start with a small cluster setup, for example with a pair of freistilbox S. Combined with the content cache, its 20 PU (Processing Units, basically PHP worker processes) deliver enough processing power for a few small and medium websites, and thanks to the redundancy we build into every hosting component, they enjoy great uptime. Scaling up is easily done by adding or replacing boxes, so the agency has full control over capacity and hosting cost at any time.
But sometimes, this model doesn’t work out as well, and that’s when the customer needs separate hosting for only a single website. There can be several valid reasons to do this:
- customers that would like to test the waters called freistilbox
- customers that want us to bill every website individually
- customers that want the website to run as isolated from others as possible
In these cases, the power of a full freistilbox cluster is just overkill. While freistilbox is the most cost-effective Enterprise Hosting Platform for Drupal and WordPress, there is actually still a gap between conventional hosting and the entry-level freistilbox setup.
It’s about time that we close this gap.
In April, we’re going to launch freistilbox Solo [1], a single-website hosting solution that has the power of freistilbox, only at a much lower price point.
[1] Yes, we’ve stolen the name from the development VM that we’ve published in 2012 and which we’re going to relaunch later this year under a new name.
Jochen Lillich
18 Mar 2015
In just a few days, the freistil IT team will again be packing their bags for our next company retreat, the freistil Days Spring 2015 . Next Monday, we’ll all meet in Rome!
5 months after our first freistil Days in Barcelona, it’s again time to meet in person and spend a few days at the same place. And after last time’s success, we’re pretty excited what we’ll learn this time living and working together!
We’re going to use this opportunity to focus for a full week on our most important projects. Of course, freistil Days are not only about work, and taking a few strolls around the Eternal City will certainly spark our team spirit and creativity. We’ve also made sure to reserve time for daily business during each day, so there’s no need for our customers to worry about being able to reach us. We might answer support requests a little bit slower than usual (and we apologise in advance) but we’ll make an effort to be as responsive as possible.
We’re going to update our Twitter account regularly (for real this time…), so keep an eye on @freistil next week!
Jochen Lillich
17 Mar 2015